
Week 3: Basic Multimedia Network Communication
HomeWork1

What are the features of multimedia?
The characteristics of media technology include: diversity, integration, interactivity In terms of data transmission requirements, it will vary depending on the data
What are the special requirements when transmitting multimedia?
It is necessary to use network transmission. In order to avoid the burden of excessive data transmission and increase the storage capacity of the computer, data compression is required, and different forms of multimedia (pictures, videos, and sounds) also have various protocols.
Please list the information services and equipment that can be called multimedia communication in the surrounding environment:
I think that the most commonly used ibon machines in supermarkets nowadays are very convenient for printing, paying bills, storing value, and purchasing tickets. Next, it should be the smart phone that is currently carried around, which can carry out various information service functions.
Choose a multimedia communication application, collect relevant information, and explain its development status and future trends
Application of wireless sensor network: For example, the development status of RFID and ZigBee is applied to wireless embedded (sensing) network or logistics supply chain management system. The future trend will be more targeted by industry players. Improve the processing and distribution of the collected data in the supply chain management system, as well as the technology development related to data security, the identification and screening of sensing signals, and the communication with the back-end database server.
What impact will the video conference system have on distance teaching? List other possible uses of video conferencing systems:
I think the impact of the video conference system on distance teaching must be positive. It makes it easier for teachers to manage student dynamics, and also has complete message boards and video functions, and can transplant the model of physical classes to online distance teaching to a certain extent.
Other uses of video conferencing, I think the progress of the Internet now, it is not like the past to reunite, it must spend a lot of time to move, although there will be a lack of part of the feeling of actual meeting, but like the current severe epidemic period, it has slowed down to a certain extent. It meets the social needs that people need to meet, and achieves the effect of calming people’s hearts.
Try to find standards related to multimedia communication on the Internet.
Common multimedia standard compression techniques:
- JPEG
- MPEG-1
- MPEG-2
The wireless network standard used by the computer:
- The first generation, based on the original IEEE 802.11 standard, the working frequency band is 2.4GHz
- The second generation, subject to IEEE 802.11b, the working frequency band is 2.4GHz
- The third generation, based on IEEE 802.11a, the working frequency band is 5GHz
- The fourth generation, based on IEEE 802.11n, the generation name is “Wi-Fi 4”, the channel width is 20MHz, 40MHz, and the operating frequency bands are 2.4GHz and 5GHz
- The fifth generation, based on IEEE 802.11ac, the generation name is “Wi-Fi 5”, the channel width is 20MHz, 40MHz, 80MHz, 80+ 80MHz, 160MHz, and the operating frequency band is 5GHz
- The sixth generation, based on IEEE 802.11ax, the generation name is “Wi-Fi 6”, the channel width is 20MHz, 40MHz, 80MHz, 80+ 80MHz, 160MHz, and the operating frequency bands are 2.4GHz and 5GHz
Wireless communication standards designed for short-distance transmission:
- bluetooth
- ZigBee
- RFID
- IrDA
- UWB
- WiMedia
HomeWork2

What are the advantages of streaming in multimedia applications?
Streaming refers to compressing a series of images and sending them to the client stably and quickly. When the protocol is enabled, you can save space without saving files on the client.
Please explain the difference between unicast and multicast broadband usage
Unicast technically requires that the MAC addresses of the NLB network interfaces of the two hosts of the two computers be exactly the same, so that the two hosts cannot connect to each other.
Multicast messages are delivered to a group of destination addresses at the same time. It uses a strategy that is most efficient because messages only need to be delivered once per network line, and messages are only replicated when lines fork.
Why is the routing mechanism needed in the multicast protocol?
The IP address used by multicast has a specific format, so once the network node finds that there is a multicast address in the packet, it will use the multicast processing method. The main problem is routing. Routers that support multicast Routing is established through the information provided by IGMP. There are many methods of multicast routing, including PIM (Protocol Independent Multicast), DVMRP (Distance-Vector Multicast Routing Protocol), CBT (Core-Based Tree) and MOSPF (Multicast Open Shortest Path First) . Multicast routing also takes into account the distribution of users, so there are so-called dense mode and sparse mode. The network domain where the user is located is also one of the technical considerations.
Please explain how the agreement on quality of service is related to streaming services?
In order to ensure quality of service (QoS), several protocols have been developed specifically for QoS requirements. Among them, RSVP can reserve resources at the network edge (edge), MPLS can control traffic, and DiffServ can specify the priority order of packets. However, in the event of network overloading, these agreements still do not work.
Explain the difference between streaming and downloading?
Streaming can be imagined as downloading while playing. It is mainly different from downloading and playing. For downloading and playing, you need to download the file to the computer and then play it. This feature allows the file to be retained, but it also causes the loss of storage space. For streaming, since the video is downloaded while playing, it does not need to be fully loaded to watch the video, and the file will not be saved on the local computer, but only exists in the form of temporary storage.
Week 4: Video Encoding and Error Repair Techniques
HomeWork3

Trying to compare the difference between the original video content and the encoded video content?
- During the encoding conversion process, there will be video distortion.
- The overall number of bits after encoding is reduced.
- Convert the spatial domain to the frequency domain.
Why do video encoding?
- The difference between the original video content and the encoded video content, most applications cannot handle such a huge amount of data.
- The original video content requires a lot of storage space. Therefore, it must be coded to reduce the burden of storage space.
- The transmission capacity of the network is limited, so coding must be done to reduce the burden of storage and transmission.
Please compare the differences and features between I, P and B frames.
- The frame that must exist in the I Frame has the largest amount of data and does not need to refer to other pictures. Without the I Frame, the GOP cannot be reorganized.
- In the amount of P Frame data, you must refer to the I Frame, and add the difference part of the picture from the adjacent solution of the I Frame.
- B Frame has the smallest amount of data and the worst picture quality. It is necessary to refer to I Frame and P Frame, and then add the different pictures.
What is Spatial and Temporal Redundancy?
- Temporal: In video data, there is usually a strong correlation between adjacent frames, and such correlation is redundant information in time. The redundant part of time is basically only a slight movement, but the actual video is similar.
- Spatial: In the same frame, there is usually a strong correlation between adjacent pixels, which is the redundant information in space. Because each point in the video is often correlated, for example, in the video of a car, the colors of the opposite points are similar between the points in the car.
- Statistical: Statistically redundant information means that the probability distribution of the symbol to be encoded is non-uniform.
- Perceptual: Perceptually redundant information refers to information that cannot be detected by the human eye when viewing the video.
“Coding” is mainly composed of which three steps? And explain.
- Representation: parameters condensed into several important messages.
- Quantization: Discrete parameters.
- Binary encoding: Use unequal quantization parameter statistics. 4.
Week 5: Video Encoding and Error Repair Techniques
HomeWork4

Why is video encoding widely used in Internet video streaming?
But high-efficiency video compression can bring huge changes to applications, solve the disproportionate gap between file size and network speed, so that videos and pictures can be spread quickly, and there is a lot of application space, so that people can now master it anytime, anywhere. Instant video information
It should prove a sentence said by the ancients: the scholars will know the world’s affairs without leaving them.
Explains the hierarchical structure of H.263.
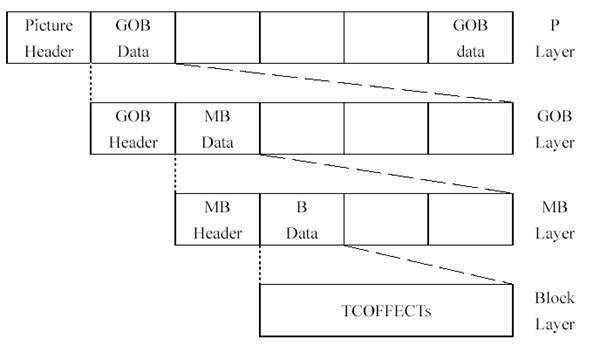
H.263 is composed of a hierarchical structure, which is divided into four layers: Picture, Group of blocks (GOB), Macroblock (MB), and Block in order from top to bottom.
-
Picture Layer
-
Group of blocks (GOB) Layer: It is mainly composed of Macroblocks with a column-like structure, forming a group of GOBs.
-
Macroblock Layer: The area covered by a Macroblock is 16*16 pixels, and a Macroblock is composed of 6 blocks.
-
Block Layer: A Block contains 8 * 8 pixels.
Try to compare the differences between H.261 and H.263.
Application of H.261: for face-to-face video telephony and video conferencing.
Applications of H.263: H.263 was originally designed for transmission in H.324-based systems (ie, public switched telephone networks and other circuit-switched-based network for video conferencing and video telephony).
Overview of H.261: H.261 is a video coding standard formulated by ITU-T in 1990 and belongs to a video codec.
Overview of H.263: H.263 is a low-bit-rate video coding standard for video conferencing formulated by ITU-T and belongs to a video codec.
Features of H.261: H.261 requires much less CPU computation than MPEG in real-time encoding. In order to optimize bandwidth usage, this algorithm introduces a trade-off mechanism between image quality and motion amplitude. That is, images that are vigorously moving are of poorer quality than relatively still images.
Features of H.263: Motion compensation in H.263 uses half-pixel precision, while H.261 uses full-pixel precision and loop filtering; some parts of the data stream hierarchy are optional in H.263, making Codecs can be configured for lower data rates or better error correction; H.263 includes four negotiable options to improve performance; H.263 uses unlimited motion vectors and syntax-based arithmetic coding.
The accuracy of H.263 Motion compensation can reach half-pixel accuracy; This method is similar to the one used by MPEG, mainly because of the characteristics of human eye vision, let us This method can be used to improve the accuracy of displacement estimation. Therefore, we can use the phase of the image in time to compress the image more. Compared with H.261, there are only integer pixels ((Integer-pixel accuracy) Overlapped block motion compensation (OBMC): After finding the most similar blocks using displacement estimation, the traditional method directly covers these blocks, and the estimated error value is added to form the current block. image. However, in H.263, all current blocks will be the weighted average of the three blocks plus the error value, but the three blocks inside will have an adjacent relationship. So the size of the block has changed from the original 16x16 to 8x8. Therefore, the quality of the compressed image will be better, and it can also maintain a better compression ratio.
H.263 compared to H.261
- Many cost reductions
- More video formats are supported
- Provide Overlapped block motion compensation (OBMC).
- Take advantage of the new Arithmetic coding
H.264/SVC video quality is divided into three adjustable modes:
- SNR scalability
- Temporal scalability
- Spatial scalability
Compare the differences between H.264/SVC and AVC
| Legacy Video Protocol (H.264/AVC) | Vidyo Video Protocol (H.264/SVC) | |
|---|---|---|
| Tolerable network packet loss rate for video conferencing | < 2 – 3 % | <20% |
| Requirements for Network | Dedicated Line | Shared Line |
| Video Conference Latency | 400ms | < 200ms |
| Video conference effect | Non-real-time interaction | Real-time interaction |
| Cost of HD conference room terminals | Expensive | Universal |
AVC is actually an alias for the H.264 protocol. But since the SVC part was added to the H.264 protocol, people used to call the part of the H.264 protocol that does not contain SVC as AVC, and the SVC part as SVC alone. H.264 SVC (H.264 Scalable Coding) was originally developed by JVT in 2004 as an extension of the H.264 standard, and was approved by ITU in July 2007. H.264 SVC is based on the H.264 AVC video codec standard, and utilizes various efficient algorithm tools of the AVC codec. Expansion kits, and are extensible in terms of video quality, and can produce decoded video at different frame rates, resolutions or quality levels. Video quality can be adjusted. The video encoding quality is better. Single or multiple bit streams can be used. Better network adaptability. When the quality of network transmission is poor, AVC cannot play the video in real time. Relatively, SVC can play the action with lower video quality. Although it cannot provide high-quality video, it improves the smoothness of video streaming.
Week 8: Video Encoding and Bug Fixing Techniques
HomeWork5

Which of the two error response mechanisms, ARQ and FEC, is more suitable for online video streaming?
- FEC must be used because when errors are found, the raw material is no longer available using the ARQ mechanism.
Please explain how ARQ works
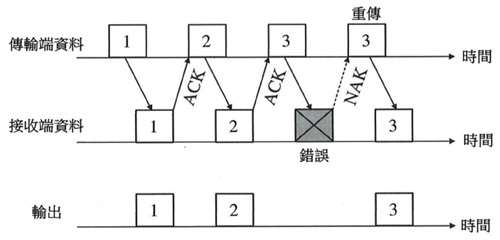
ANS: When the server and the client want to transmit data, if an error occurs during the transmission of the message, the receiver will reply to the transmitter, and there are three common methods: Stop-and-wait Automatic Repeat Request:
- Each time the sender transmits a data packet, it temporarily stops and waits until it receives the ACK/NACK returned by the receiver (Receiver), or decides to transmit new data/retransmission when the ACK/NACK has not been received after a certain time. .
Go-back N Automatic Repeat Request:
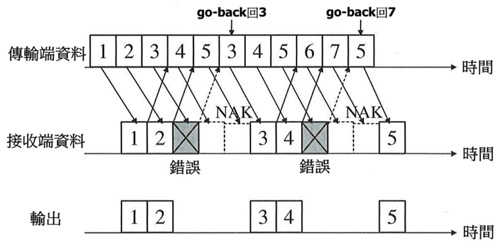
- The sender continuously transmits data packets. If it receives ACK, it does not change its action, but when it receives NACK, it will jump back to the wrong data packet and retransmit it in sequence. After returning a NACK, the receiving end discards the next received packet, and continues to store the data packets in sequence only after the previously wrongly transmitted data is correctly decoded (received).
Select Repeat Automatic Repeat Request:
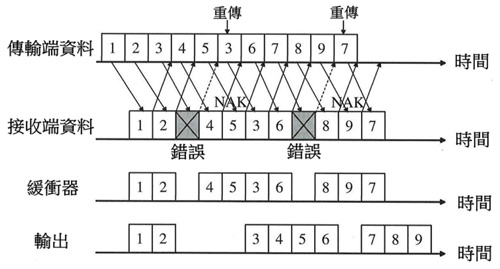
- The method is similar to Go-back-N ARQ, but when receiving NACK, only the wrong data packet is retransmitted instead of retransmitting in sequence. In addition, the receiving end does not discard the next received data packet after returning NACK The packets are stored in a buffer (Buffer), and they are rearranged in sequence after all the data is received (correctly decoded).
Please explain how FEC works?
ANS: The basic FEC transmission operation. When the Server wants to transmit k bytes data, it will first perform an encoding operation through the FEC encoder to generate (n-k)=h bytes and transmit it together with the original data k bytes, and allow the loss of h bytes or error, when an error occurs during transmission, the client can already use the received k bytes to decode the data by the FEC decoder. If the error occurs within the h bytes error, the erroneous data can be restored. and reconstruct the original data.
Try to compare the difference between ARQ and FEC error response mechanism?
ANS: Automatic Repeat-reQuest practice: When data is lost, retransmission of unreceived data is required. advantage: Just resend the lost data. shortcoming: Timeliness and a lot of lost bandwidth consumption. Forward Error Correction practice: With some additional information, when the data received by the receiver is incomplete, it can be repaired and restored through the additional information.
advantage: Some errors can be fixed without relying on server resend.
shortcoming: Consume additional bandwidth and resources.
Please explain the difference between Packet-Leavel FEC and Byte Leavel FEC?
ANS: Byte-level FEC is the correcting codes, usually used in the physical layer. In FEC(n, k), n is the block size, which means that it contains k message symbols and n-k parity symbols to provide error correction at the decoding end. One symbol corresponds to For a set of bit sequences (such as bytes), it is impossible to know which symbols have errors, so correcting codes can only repair (n-k)/2 symbol errors at most. The general correcting codes cannot resist the occurrence of a large number of error bursts, so they are usually transmitted with interleaving, in order to disperse errors and reduce the impact of bursts. Packet-level FEC is erasure codes, which are usually used in Transport or Application layer. In FEC(n, k), n is block size, including k data packets and n-k parity packets, because we can know which ones are above the IP layer. There is an error in the packets, so we use erasure codes, that is, assuming that MH can correctly receive any k packets out of n packets, any missing data packets will be correctly reconstructed.